LIVE DEMO "HUMAN POSE"
Example of OpenVINO(details) framework in a docker container
The use case is the hypercompression of video streams by a local extraction of meta data via Artificial Intelligence. Typical applications are remote surveillance, detection of prohibited gestures/attitudes, anonymisation of surveillance.
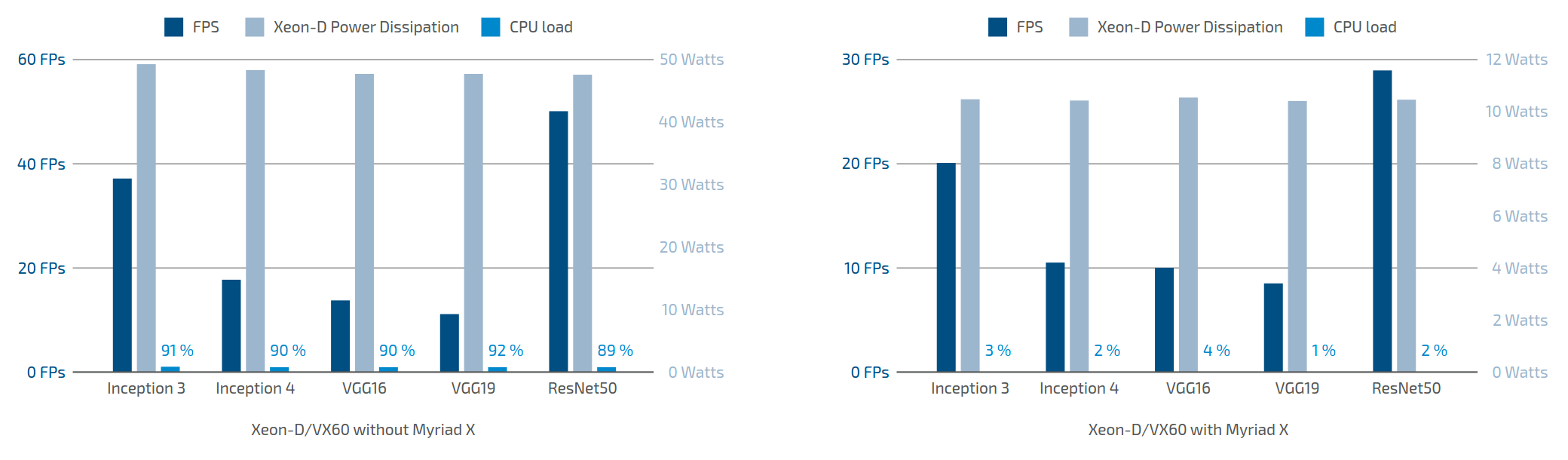
Neural Network Acceleration with MOVIDIUS/INTEL Vision Processing Unit (VPU)
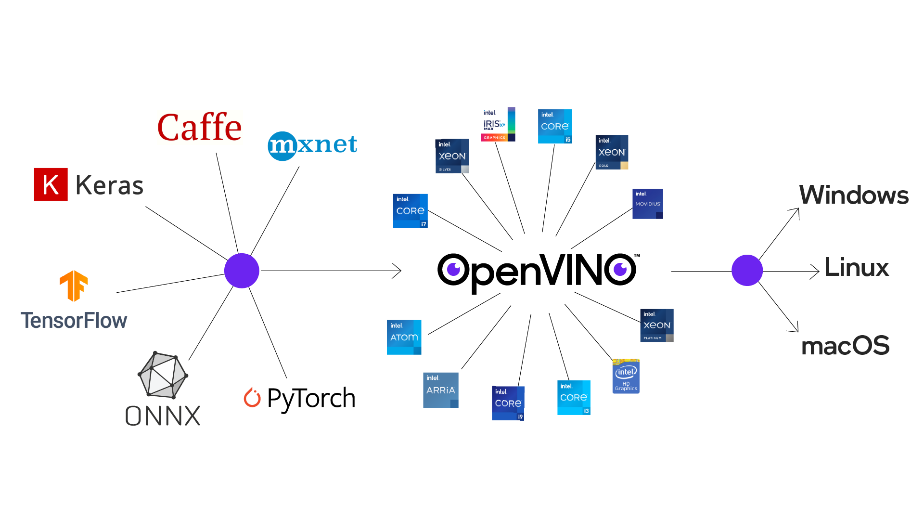
AI software INTEL OpenVINO inference framework as a container on guest Linux OS
OSSEC-Line hypervisor based on LINUX OpenWrt, hosting application in VM(s)
Remote management consolewith SEC-Line OpCenter

For a guided demo on Human Pose/OpenVINO and other AI demos, please contact us through the form Request Live Presentation More information about OpenWrt secure hypervisor and SEC-Line OpCenter management console can be found on SEC-Line demo page.